

On Track Off Roads Adam Wheeler released an article this week on the OTOR website with the focus on data and how it is used in MXGP.
In the article, Adam writes about his interaction with the topic over the last 10 years, and what the current view in the paddock is on working with sensor technology on dirt bikes. Around the mid 2000’s to early 2010’s, we saw the move to data acquisition in motocross, most notably with Chad Reed’s TwoTwo Motorsports Honda, but little has changed in terms of the actual hardware or software since that time. There are a myriad of things that can be measured in motorsports all based around temperature, pressure, flow rate, strain and position, but of course our focus here at Motoklik is on suspension.
So what are the current views on suspension data acquisition in motcross? Thanks to Adam, we have some answers on hand:
Roger Shenton, Team Co-Ordinator, Team HRC: We’ve used sensors on suspension for a few years but we never race with it. It’s delicate. We have to use a harness and the bike carries more weight, so we put it on only for pre-season and mid-season testing to know what the suspension is doing and not just for rider feedback but to see what our technology is doing. We don’t incorporate it with racing at all.
Wim Van Hoof, Technical Manager, Standing Construct Honda MXGP: I know they use sensors on the suspension in the U.S. and in supercross I can understand it as the track changes little compared to motocross, and how many times a season do they have a mud race?! They don’t have braking bumps like we do or changing lines. If we put sensors on our suspension then after two-three laps the data will have changed, and from where can you make the comparison?
Harry Norton, Red Bull KTM Factory Racing Team Technical Co-Ordinator: Being able to understand the exact forces on the suspension is useful. If you could put suspension data over engine data on the track then you’ve got a really clear picture of what is happening. For sure there are already people looking into this and I think it will be a priority for teams in the future.

As per Roger, Wim and Harry, suspension data is used at MXGP and Supercross level, but there are two main challenges, reliability and changing track conditions.
In the picture above, you can see the types of sensors most commonly used today. This is a carry over technology from tarmac based motorsports and not built particularly with motocross in mind. While that sensor technology works brilliantly on-road, some of the issues faced by these sensors in off-road are:
- Contact parts and electronics get exposed to sand, water and grit causing them to fail prematurely.
- Shafts bend during high speed movements.
- Return springs aren’t fast enough to measure high speed compression movements accurately.
- Accuracy can be reduced from changes in pressure due to temperature and oil volume fluctuations.
What has Motoklik done to overcome these problems?
We knew from the outset, that a reliable system is key to making suspension data work in motocross. This is the reason why we developed our own brand new type of sensor (shown in pictures below) that solves all of the issues outlined above. How did we do that? Magnetism! Magnetic field strength is an amazing feat of physics. It’s ability to pass through materials eliminates the need for contact parts, however, until now the distance that could be measured was limited by how sensitive the sensor was. The new Motoklik sensors work over longer distances and adapt to changes in the position of the magnet in the x, y and z axis’s making them incredibly versatile, and who knows maybe we will see them used in other professional motorsport in the near future 😉

Our first problem of reliability is now solved, but what about the ever changing conditions? Surely a track that’s lines and roughness change from lap to lap can’t be interpreted through data…
If we put on our data scientist hat here for a minute, what’s really being said is that motocross suspension data has a really high standard deviation value. Standard deviation is a measure of how spread out the data is that has been recorded.
An example would be the heights of people. If we had a classroom full of 5 year old’s, and we measured their height, we would get an average of 109cm ± 4cm. If we measured a room full of adult men, it’s 1,778cm ± 8cm. The standard deviation is the ± bit, and just because adult men have a higher standard deviation, it doesn’t mean we can’t make relatively accurate predictions about their height, in the same way that just because motocross suspension data has a higher standard deviation than road race data, it doesn’t mean we can’t apply data analysis techniques to it.
The trap that you can easily fall into is focusing on one specific issue at one specific part of the track. Suspension setup in motorsport is a compromise. We need to have a wide view of all opinions (or in this case data) to make a fair decision. This gives a clue as to what one part of the solution is when analysing suspension data in motocross.
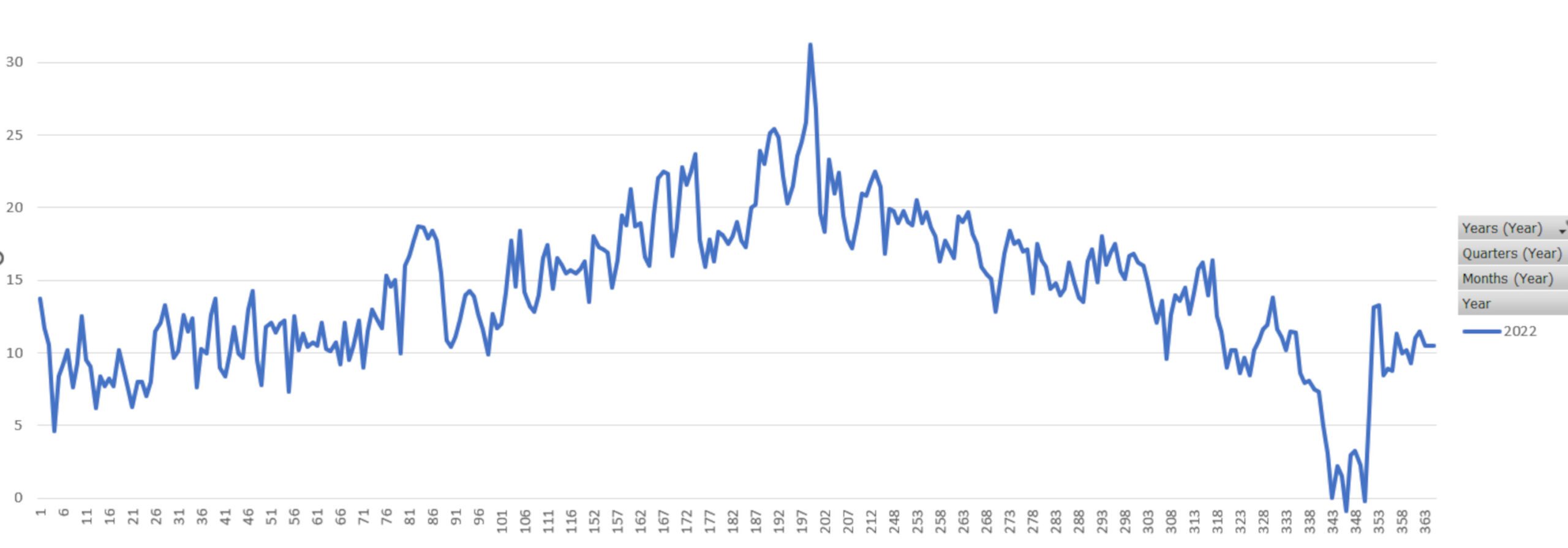
Let’s work through an example again, and this one is close to my heart, the temperature on a given day in Ireland. The graph above is the maximum temperature from everyday throughout 2022. We can see a bit of a trend there as we go from Winter into Summer, and back to Winter again, but a prediction as to what the temperature is going to be on a certain day is very difficult to make with any level of accuracy. This is what happens when we look at suspension data for one specific section of track, or one specific lap. We’re trying to make a prediction with a low amount of historical data.
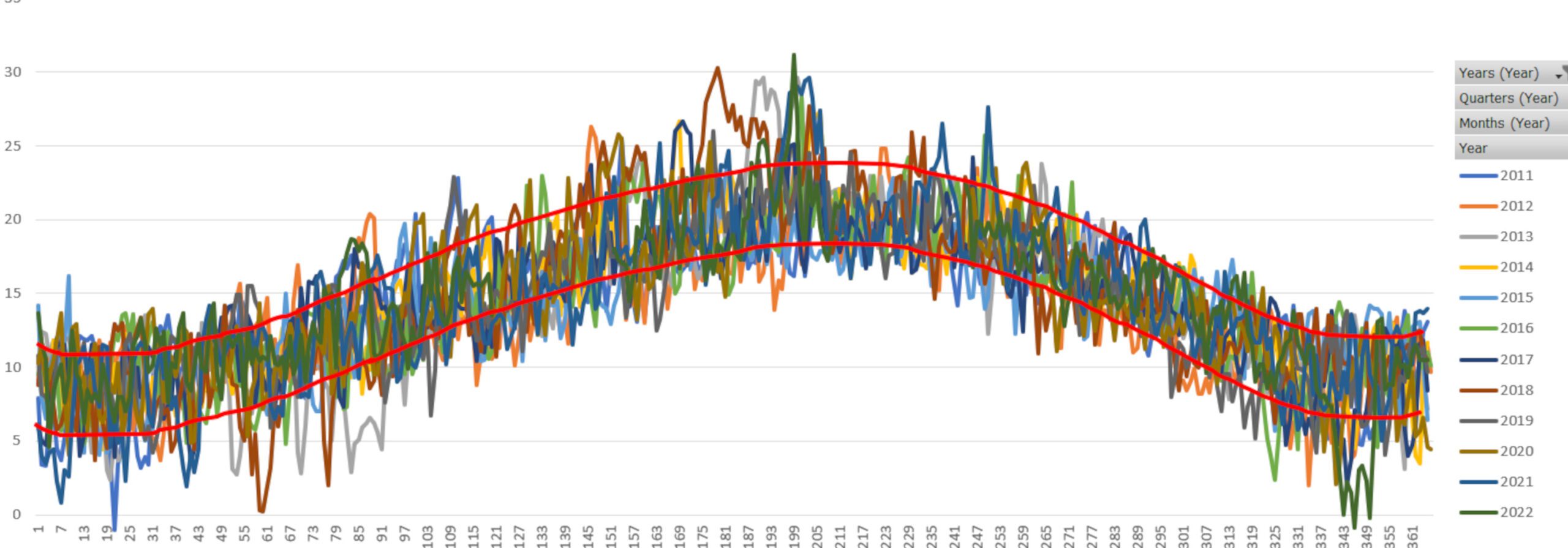
When we add in data from the last 10 years, things become a lot more clear. We can see how most of the data lies inside the two curved red lines, so on any given day we can make a prediction within around ± 2.5°C. The accuracy of our prediction can be further improved if we add in more data such as humidity, atmospheric pressure and cloud cover. This is what’s possible when we have enough suspension data to work with also.
So why hasn’t that been done before?
I believe the answer lies in the reliability of the current sensors used, and the individuality of the data recording. With race teams and manufacturers having to work on their own, it’s very difficult to record enough data with such a small group of riders. There is a lot of time already spent on trying to test cams, gearing, ecu maps, triple clamps, linkages, tyres, handlebars and so on, it leaves very little time to dedicate to suspension data recording especially in Europe with bad weather and the sensors may not last more than a couple of laps.
This is where Motoklik has such an advantage. We can reliably and continuously monitor and record the data from 100’s and 1000’s of riders from all over the world in every type of condition to build a vast data base of suspension data to make predictions on setup, in the same way that Google uses internet browser data to predict what items you might be interested in buying, or where you’d like to go on holidays.
There is a lot more that can be done to improve the accuracy of our predictions for suspension setup, but as you might think, it starts getting tricky to do it on your own if you are separating out the data into multiple features and combining it with a huge historical data base. This is where Artificial Intelligence comes in, but I think that is a topic for another day ![]()